Architecture of a Wheelchair Control System for Disabled People: Towards Multifunctional Robotic Solution with Neurobiological Interfaces
The aim of the study was to develop a control system for a robotic wheelchair with an extensive user interface that is able to support users with different impairments.
Different concepts for a robotic wheelchair design for disabled people are discussed. The selected approach is based on a cognitive multimodal user interface to maximize autonomy of the wheelchair user and to allow him or her to communicate intentions by high-level instructions. Manual, voice, eye tracking, and BCI (brain–computer interface) signals can be used for strategic control whereas an intelligent autonomous system can perform low-level control. A semiotic model of the world processes sensory data and plans actions as a sequence of high-level tasks or behaviors for the control system.
A software and hardware architecture for the robotic wheelchair and its multimodal user interface was proposed. This architecture supports several feedback types for the user including voice messages, screen output, as well as various light indications and tactile signals.
The paper describes novel solutions that have been tested on real robotic devices. The prototype of the wheelchair uses a wide range of sensors such as a camera, range finders, and encoders to allow operator to move safely and provide object and scene recognition capabilities for the wheelchair. Dangerous behavior of the robot is interrupted by low-level reflexes. Additional high-level safety procedures can be implemented for the planning subsystem.
The developed architecture allows utilizing user interfaces with a considerable time lag that are usually not suitable for traditional automated wheelchair control. This is achieved by increasing time allocated for processing of the interface modules, which is known to increase the accuracy of such interfaces as voice, eye tracking, and BCI. The increased latency of commands is mitigated by the increased automation of the wheelchair since high-level tasks can be given less frequently than manual control. The prospective solutions use a number of technologies based on registration of parameters of human physiological systems, including brain neural networks, in relation to the task of indirect control and interaction with mobile technical systems.
Introduction
Today nearly 10% of all disabled people, or 1% of the Earth population, need wheelchairs [1]. For various reasons about 40% of them are not provided with specialized wheelchairs [2], and many of the available vehicles are not well suited for specific patients. Therefore it is extremely important to create multi-functional wheelchairs, taking into account all types of functional disturbances. Modern mechanized wheelchairs allow direct manual movement control, usually with a joystick, and many people with impaired motor functions cannot use them. The modular control system of a multifunctional wheelchair proposed in this work allows disabled people with severe functional impairments, including complete paralysis, to move.
There are two main ways to interact with disabled persons. The first way is to use new types of interfaces between people and technical devices. The second one is to simplify the process of interaction through the intellectualization of technical devices and the expansion of their functionality. This work describes the development of an integrated system for human interaction with a robotic wheelchair for disabled people. The combination of new types of human-machine interfaces (HMI) and the intellectual control system creates a new quality of control. In the end, the wheelchair for disabled persons should implement the functions of delegated autonomy, solving a set of local and global control tasks automatically. On the other hand, the developed interface should provide control methods of the wheelchair to the user, both at the operational level and at the task and behavior levels. In other words, user instructions should be interpreted as high-level control sequences, and the entire interpretation and execution of elementary commands should be performed by the autonomous control system. It is assumed that the application of such an interface at the top level will facilitate the wheelchair control process and will make it practically useful for a wide range of disabled people as well as increase the accuracy and speed properties of the wheelchair. It should also be noted that the use of an autonomous control system with high-level commands allows developer to extend the range of applicable HMI, including slow neural interfaces based on electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS), which cannot be applied to direct control at the lower level. So far, such interfaces do not give an acceptable rate of receiving commands to implement operational control. However, some lower-level commands as an emergency abrupt stop-command should be in the system anyway.
Thus, the basic architectural model of the control system for the robotic wheelchair is a service-oriented transport system with autonomous control facilities. The multimodal interface for human-computer interaction will provide tasks at the top level of control hierarchy. Direct operational control is also optionally possible.
Wheelchair control systems analysis
The most important part of automated robotic wheelchair is a thoughtful method of user interaction. The interfaces of many modern complex technical systems allow disabled persons to work with them successfully, but in the case of the wheelchair, their requirements are particularly diverse. Virtually any known method of interaction is unsuitable for a certain group of users. Robotization of the wheelchair is further complicated by the requirements of real-time control under extremely diverse outer conditions. Also an error cost can be very high.
Since the time as automated wheelchairs began to move using their own power, a large number of ways to control them has been proposed. These methods could be classified according to the type of control signals, taking into account that often different types of user interaction are combined.
If a person has the following functions intact: (1) the motor functions of the limbs, (2) vision, and (3) higher mental functions, then it is easy to organize direct wheelchair control using traditional means: buttons, joystick, steering wheel or pedals. However, in case of violation or weakening of at least one of the listed functions, direct control becomes difficult, impossible or dangerous.
In this situation, there are two possible ways of development:
1. Attempts to restore the damaged function with the help of other safe functions to the level necessary for direct control.
2. Implementation of an indirect control scheme in which the operational control of the movement is carried out fully automatically, and the person sets only high-level commands: end points of the route or any additional actions.
The first strategy has a long history of development. For example, ordinary glasses can correct some visual impairment. The use of electromyographic signals from the intact muscles allows a person to replace certain motor functions. The use of the eye tracker allows direct control of movement in case of a significant violation of muscle activity.
However, in some cases it is not possible to achieve the required speed or accuracy of the control. Thus, existing neural interfaces based on electroencephalogram or fNIRS have a time resolution measured in seconds under optimal conditions [3], and are not suitable for direct control. To restore some possibilities of vision, the devices, that verbally describe objects appeared in front of a person, are recently developed [4]. They are undoubtedly a breakthrough for people with visual impairment, but their speed is also not enough for the direct control of a moving wheelchair. As for higher mental functions, the means for facilitating them in real time are only at the research stage.
The second strategy allows us to bypass the limitations associated with the low speed and unreliability of natural or restored functions. For example, for the automatic control system, a low rate of high-level commands is allowed, on the order of several minutes, which is available for all existing neural interfaces. Such a control scheme is protected from errors, since all commands in it are permissible, and operational control is carried out automatically, and it can be applied even for people with certain types of impairments of higher mental functions, which is impossible for direct control systems.
In our implementation, we use a combination of these strategies:
1. The possibility of direct control with a joystick.
2. Facilitation of motor functions for direct control using an eye tracker and electromyography.
3. Implementing indirect control with high-level commands. Commands can be given using various accessible functions: speech, limb movements (buttons, joystick), eye movements (eye tracking), muscle activity (electromyography), electric brain potentials (EEG), changes in brain blood flow (fNIRS) or any other. It is also possible to duplicate the means of giving indirect commands to increase reliability of the system.
Let us consider possible HMI suitable for direct and high-level control in more detail.
Voice control system for wheelchair was described many years ago [5]. The first systems usually recognized words from a predefined instruction set. Linguistic methods of command recognition in a language close to natural were developed later. Accuracy of the recognition was about 97% [6]. With a fairly rich recognizable language, it was possible to set high-level tasks understandable for humans. This type of interaction has some drawbacks such as vulnerability to extraneous noise and the need for operator to pronounce commands clearly.
One can use the signals that occur in the muscles during tension for control. With this approach, a set of simple commands to move in a certain direction or to stop maps to certain signals from sensors that record the electrical activity of the muscles. For control, facial muscles [7, 8], torso, neck [9], hand muscles [10] could be used. As a rule, the read signals generate commands that set the motion direction, as in the case of joystick control. False positives due to accidental muscle contraction, including fatigue, are a significant problem for such systems (for example, in the last of these studies, the percentage of false positives reached 50% for individual muscles).
There are designs that use the direction of gaze to control movement. This approach is very promising, since it can allow one to move independently, even to those who cannot use either voice control or muscle tension. Types of input signals for such systems are very diverse. Sometimes the movement of the eye acts similarly to the movement of the joystick. In other cases, the user has to fix his gaze on the areas of space where he would like to move, and the control system should independently calculate the trajectory to achieve the goal. This method allows to increase the level of control tasks.
Eye movement tracking poses a number of important issues. It is necessary to enter the movement mode in and out using specific gaze patterns that are not found in motion control. It is also necessary to distinguish between controlled, deliberate displacement of sight from accidental, caused by involuntary eye movement or fatigue (the problem of “Midas touch” [11]) and from control over the execution of a previously given command. Because of this, the complexity of the signals that can be sustained by a person and recognized by the control system is limited. A more complete discussion of this problem is given in [12]. Among the proposed methods of dealing with false positives, the fixation of gaze on a certain object for a specified time (about 0.5 s) can be mentioned [13] as based on the earlier estimation of communicative gaze fixation time [14].
Methods are being developed that use encephalographic data [15, 16] reflecting the electrical activity of the neural networks of the brain in cognitive processes, to control computer devices. Their advantage is the possibility to consider brain activity in any, even a fully paralyzed patient; therefore the coverage of users is wide. However, this approach has significant drawbacks: the operator needs an assistant to prepare the data for reading, high-quality hardware is required to obtain the EEG, the proportion of erroneous readings can reach 50%. For example, due to the difficulties of correct reading in [17], the read time of the stop command reached an average of 5 s, which is unacceptable for practical use. However, it is also noted there that with higher-level control (indicating the end point of the route) and greater intelligence of the wheelchair, reliability and speed of work should increase.
Recently, research has been conducted on the use of fNIRS technology for the tasks of brain–computer interfaces. Since this technology is based on changes in the blood flow of the human brain (correlated with the electrical activity of the brain neural networks), its speed is measured in tens of seconds per command [3]. The use of combined EEG-fNIRS systems can increase the speed to a few seconds and the accuracy of command classification up to 96.7% [18]. These speed and accuracy are suitable for giving high-level commands to robotic devices, but are still too slow for direct control.
As can be seen from the above, many modern control methods have significant advantages, but it is impossible to choose one of them that will suit well all groups of patients. Since errors in control signals of different recognizers often occur independently, the quality of work can be improved by combining different types of interfaces that record many different physiological indicators of the same cognitive process. Numerous solutions have been proposed, for example, combining gaze movement tracking and a computer vision system to track features in the operator’s sector of view [19]. This interface tracks objects that the eyes are pointing at and makes an assumption whether the observed movement pattern has been a control signal or not.
General wheelchair architecture and interfaces
Thus, the developed architectural solution should work with a wide range of interface devices. However, all the mentioned user interaction methods have drawbacks that make operational, low-level wheelchair control unreliable and unsafe. The command recognition accuracy is low, and fundamental physiological limitations prevent it from improving. At the same time, command delays of the interfaces are too long for comfortable and precise operational control.
These limitations can be overcome by delegating control to a higher level. Instead of low-level commands, the movement can initiate high-level actions consisting of a set of commands that are generated and controlled by an intelligent wheelchair control system. This allows reducing the requirements for the interface delays and mitigates problems that may arise from incorrectly recognized commands.
A high-level control system allows combining interfaces that are best suited for a particular operator. Some interface devices are suitable for both low-level and high-level commands (joystick, myosensors, eye trackers) while others can be used only for high-level command recognition. To work with devices of different classes, the system must be able to analyze commands from different levels simultaneously and thus it must have a powerful method for describing complex behaviors composed from simple ones.
Implementing high-level control to solve the problem of delays in the operational (low-level) control gives rise to the problem of defining user commands. Since high-level commands have a large number of different variations and can be associated with observable objects, in contrast to low-level motion commands, it is necessary to use models and methods capable of working with these concepts. One of the approaches is a control architecture based on semiotic networks [20] (thereafter it would be called semiotic control). Methods based on ontologies, for example, RoboBrain [21] and SO-MRS for multi-agent systems [22], are also capable of working with objects and concepts, but they focus on the transferring knowledge of concepts between robots, as well as on the binding of objects and concepts. At the same time, such conceptual system acts as an external source of knowledge. In the proposed approach, on the contrary, the semiotic structure is an integrating mechanism — the semiotic network unites in a single system the mechanisms for activating actions, description of the model of the world, agent goal-setting and provides connection to the natural language commands of the operator. Since commands (and even just statements) pronounced by a person can be conveniently represented by a description that operates on concepts, it is natural to transfer them to a control system that plans actions based on a network of concepts.
Automatic wheelchair control problems that arise at a lower level can be handled separately. The mechanisms that should be implemented in a wheelchair control system are the following.
1. Low-level reflexes. Reflexes of the lower level are responsible for the braking of the wheelchair in case of an emergency situation — detected possibility of a collision with an obstacle, danger of falling from a height, etc.
2. Computer vision system. Since the interface involves communicating with a person, some high-level commands will, in one way or another, be in human terms. So it is natural to expect a command like “drive up to the table”. In this setting, the sensor system must be able to find a table in the surrounding space for the control system to be able to build a route to it.
3. Navigation and localization. Landmark (or other objects) recognition and map building capabilities are essential for successful navigation in a natural environment.
4. Trajectory building and following. This system must be able to bring the wheelchair from its starting position to the position requested by the user, while avoiding collisions and dangerous zones.
Semiotic world model of the robot
The main element of the control system is a semiotic network [20], that consists of signs and links between them that are built using a set of rules. The mechanism for describing the system is a first-order logic grammar. The intelligent wheelchair has a multi-level control structure: it has its own sensors, effectors, a system of reflexes, and some other low-level elements. All these elements are connected to each other by the semiotic system which describes perception elements (sensors), actions and contains names of the corresponding signs. The names of signs allow us to connect the semantic networks formed by the text command analysis system and the semiotic network that serves as a model of the agent world. At the same time, individual elements are combined into signs, which can be further connected into more abstract high-level constructions (for example, the “living room” sign, which is a subclass of the “room” sign). Since the system is capable of working with a limited set of concepts defined by sensory capabilities and embedded low-level action algorithms, a fixed vocabulary of symbol names (object types), attributes, and actions is used as a description of the interface between the speech analysis system and the semiotic control system.
Signs describing a world model are made up of closed atomic formulas of first-order logic (statements) and STRIPS operators, which are triples (productions R) of the following form:

where C are the preconditions of the operator, A is the addition list of clauses, D is the deletion list.
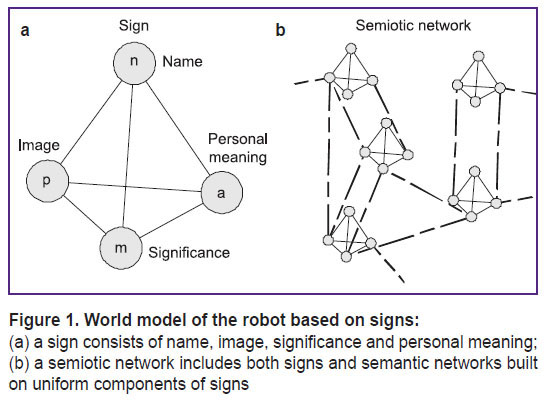
All entities perceived by an agent in the semiotic world model are represented as signs. Formally, each sign is described by an ordered set of four components (Figure 1):

where name n connects the elements of the semantic network of a command obtained from speech analysis and signs in the semiotic control system;
percept p consists of observable (or otherwise inferred by the sensory system) assertions about the signified entity;
the functional meaning m is a set of STRIPS operators (1), which allow to get information about the world that is not directly observed with the help of inference (note that this inference can use information from multiple sensors unlike the inference mentioned in the percept description);
personal meaning a consists of a set of actions related to the sign, each of which corresponds to a STRIPS operator (1).
|
Figure 1. World model of the robot based on signs: (a) a sign consists of name, image, significance and personal meaning; (b) a semiotic network includes both signs and semantic networks built on uniform components of signs |
The semantics of a specific action is a low-level (outside the sign system) algorithm implemented by standard control methods, for example, a finite state machine. The semantics of a percept p are the algorithms of perceptual recognition, which directly determine the presence of this property in the observed object (or, in general, in the scene).
The description of signs and connections between them is carried out using first order logic language. Triplets of conditions, additions, and deletions are STRIPS operators, which are used exactly once during a logical inference step in a certain order. During a planning step they can be used in an algorithm similar to the STRIPS method [23], but using a semiotic description of the problem. It must be noted that STRIPS planning was also used in control systems based on a semiotic network in the work [24], albeit in a slightly different manner. Nevertheless, it still shows the applicability of the method to this type of models.
The STRIPS planning algorithm uses a variable state in the form of a list of true facts and uses operators to search in the state space. In the method we propose, these operators are also used to supplement and update the facts about the new state of the world in the semiotic model not just during planning, but also during action execution. The state of the world is preserved between successive actions of the robot. This means that the order of application of operators is important, and the logical system constructed can be non-monotonic. Despite these problems, this method speeds up the updating of facts about the world at every step by preserving those facts that were previously derived, if they do not contradict the new data. It also functions as a memory mechanism when facts that are not directly derived from current observations, remain in the knowledge base of the agent.
Different implementations of actions can be used at the lower level, for example, finite automata or hierarchical strategies. Both methods have a natural way to discretize control — the transition between states. Depending on the implementation such a transition can take place at the completion of the most basic action in the hierarchy. In the intervals between such actions, the control goes through the rest of the cycle: the data from the sensors is used to update the semiotic network, which is the knowledge base of the agent, logical inference happens, then planning and processing of the user commands.
The activity of an intelligent agent is provided by intentional mechanisms. These are the algorithms of the system and the data structures associated with them which initiate agent actions aimed at accomplishing any goal. One of the reflex levels is implemented outside the semiotic system (which is responsible for “cognitive” processes) at the lower level for safety reasons — it is able to intercept control to avoid collisions. In addition to user commands, the system must also consider the environment and take care of the operator safety. The execution of a command may require a number of different sequential actions interrupted by reflexes in a changing environment and subsequent re-planning. This leads to the need to consider the user’s command as one of the goals of the intelligent control system that should be achieved in the process of execution, but not the only one. Instead it should be considered as a constraint, but the system itself has to be designed based on its own activity and a set of internal mechanisms governing its behavior. An example of an architecture that supports the concept of autonomous goal setting is emotion-need architecture [25]. However, it is difficult to add external control in the form of commands into such a system without modifications. Instead it is possible to partially describe the needs using a semiotic representation in the form of rules that are part of the functional meaning (m component of the sign). The choice of the satisfied need is supplemented with an algorithm that is external with respect to the semiotic model.
To make a decision about the next action, the agent must also determine which of the preconditions of actions in personal meanings are fulfilled. The expressions in the conditions of the rules are checked against the facts added by the operators from the functional meaning of the signs (m part of the sign).
Robot control system
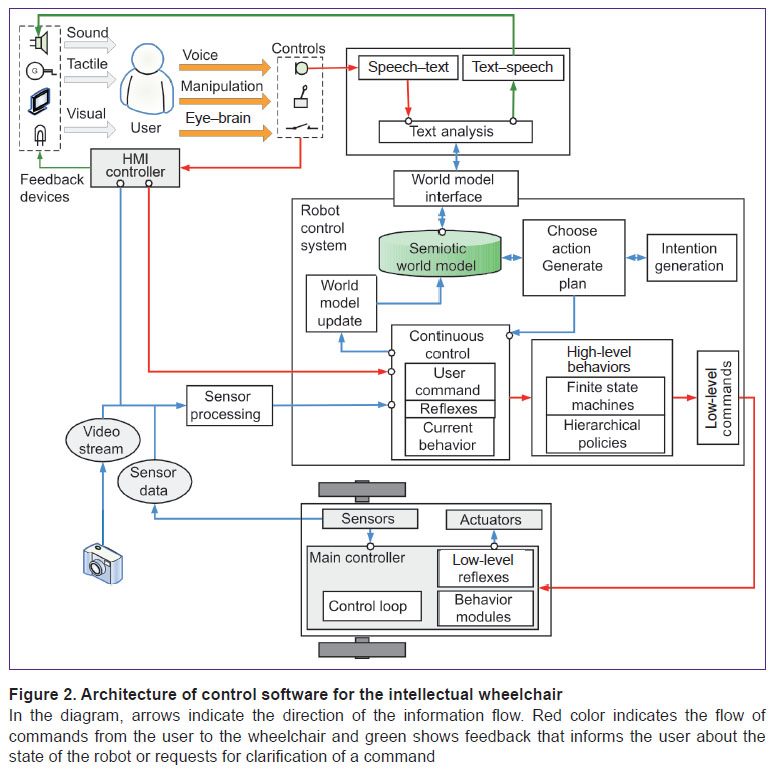
The software architecture of the system is depicted in Figure 2. The control system has multimodal input and output, which, whenever possible, duplicates functionality to support the largest possible number of users with various disabilities and provides an effective interface for interacting with the wheelchair.
|
Figure 2. In the diagram, arrows indicate the direction of the information flow. Red color indicates the flow of commands from the user to the wheelchair and green shows feedback that informs the user about the state of the robot or requests for clarification of a command |
The input system consists of a sound input, mechanical manipulators (joystick, buttons), eye tracker oculomotor control system, myogram-based neural interfaces, electroencephalogram, and fNIRS. The standard mode of operation involves giving high-level commands, i.e. setting goals for an intelligent wheelchair, however, the possibility of activating a lower-level (operational) direct control for movement is also provided. The feedback for the user consists of voice messages (for example, reporting the impossibility of executing a command or asking to clarify a command), screen output, as well as various LED indications and tactile feedback system signals. These two systems of HMI devices are connected to a computer either via an HMI controller or directly.
The lower level that works directly with the hardware has a camera, a set of various sensors (range finders and encoders), actuators (motors) and the main controller that coordinates the interaction with the computer. The main controller of the robot uses almost raw sensor data with minimal preprocessing and implements simple low-level behavior patterns, such as moving forward without collisions, moving along a wall, avoiding obstacles, etc. It also has a rangefinder-based reflex system that can block dangerous low-level actions at any time in order to avoid collisions. The video stream is sent directly to the image processing system of the computer. The rest of the sensor data is also processed before being used in the control system at the computer side.
At the top level, the control system is based on a semiotic model of the world. It receives the processed data in the form of objects, the relations between them, relative positions of the obstacles, which are supplemented by the logical inference based on the information stored in the signs known to the system. Planning is done using the semiotic system and it either selects the current action directly or returns a plan as a sequence of high-level actions (behaviors). At the same time, the activation of the planning and execution of actions can be triggered by several different mechanisms: a direct user command or the internal intentional system. The latter is involved in the process of selecting the current goal, even if the user has set some goal for the system. This is necessary in order to enable the system to balance the safety of operation and the immediate fulfillment of the user’s desire. The planning, intentional and world model systems are connected by the continuous control module, which, at each step of the system, launches the necessary processes for updating the world model, planning, monitors user commands and sends high-level commands for execution. It also contains another system of reflexes that can interrupt dangerous behavior of the wheelchair based on the analysis of sensors that is available only to the high-level system and cannot be tracked at the level of the main controller.
High-level commands (behaviors) can be implemented in different ways and are not described directly in the sign system: it only contains information about their availability, conditions for activation and expected consequences. It is convenient to use, for example, finite automata or options (hierarchical strategies mentioned in the context of reinforcement learning [26] as their implementations). They send low-level commands to the controller. For example, a “find object” behavior can use movement commands, avoidance of obstacles and movement to the observed object using the camera.
The speech interaction subsystem consists of a speech-to-text, text-to-speech module, and a module that analyzes a text message and transforms it into semantic networks that are transmitted as commands to the wheelchair control subsystem. The user receives the results of executing commands or requests for clarification verbally using the text-to-speech module, and the commands are entered by the module speech-to-text. Language for interaction with the user is close to natural. In particular, by determining the insufficiency of information in a command, the control system based on the sign model can generate requests for clarifying ambiguous orders. The speech module communicates with the control system using a special module that uses a dictionary of concepts. The dictionary contains concepts such as attributes of objects that the user can use in the descriptions, types of objects and known actions. It is used to convert the semantic network recognized by the text analysis module into a fragment of the world model, for verification of the possibility of such a transformation, and for sending a request to clarify the elements of a command or a message for the user about its unattainability if it is necessary.
An example of a semiotic description of the intellectual wheelchair’s world model is shown in listing Table 1. This description includes the signs “wheelchair”, “bedroom”, “living room”, “room”. Each sign is described by statements about their type (object “bedroom” is a “room”) that forms one of hierarchies in this network, as well as statements about attributes (“dest” is present appointment, “pos” is position; “S” is sign’s name unique for each sign). Each sign description starts with a “#”, after which a list of percept predicates follow (“p”), functional meanings (“m”) and personal meanings (“a”). Each operator is described by a name, preconditions listed after “?”, added facts after “+” and a list of deletions after “–”. Ground variables are written with a capital letter. The name of the current sign is denoted as “S”.

|
Table 1. Semiotic description of a world model |
The described model contains operators from “m”, which allow to derive new facts from known ones related to the sign: the “connection” operator states that if there is a door between rooms in one direction, there is also a passage in the opposite direction (the commutativity of the door predicate).
The actions of the model (“a” part of signs) are described in the form of STRIPS operators “move1”, “move2”, “walk” that contain conditions, adding and deleting facts. In the example all actions belong to the “wheelchair” agent.
The autonomous agent in the example has active intentions in the absence of special external incentives or the command of the human operator to illustrate the concept. Of course, in the real system motivation of the robotic agent should be arranged so that it only reacts automatically in various undesirable situations, rather than independently performs any actions. The initial state of the system is described in the “Starting state” part of the listing of Table 2. “Wheelchair” knows that it is in the “bedroom” now, it has no appointment, and also has information about world’s topography: presence of “living room” and a door from the “bedroom” to the “living room”. In the example, no emotional or other goal setting mechanisms are used, so the agent chooses the first possible action in a given situation. In a real application an external intentional system should be used to choose an appropriate action instead. This system is not described within the sign system. The “walk” statement is the only action that is available at first step, so it is chosen and the agent’s knowledge base is updated in accordance with the added and deleted lists (that is, the appointment is “to move to the living room”). In the next step, an action is performed according to the goal that is now stated in the agent’s command (the predicate “dest”). This example does not reflect an intermediate step performed before the next significant processing of the situation that is updating the percepts in accordance with the observed situation from the sensors. It is important to note that such a step may introduce conflicting facts into the knowledge base. In this case it is necessary to repeat the logical inference using all applicable operators from “m” and considering the data obtained from the sensors to be true in any conflict situations. Thus, the described sign system implements autonomous behavior with goal setting by an intelligent wheelchair.

|
Table 2. Example of inference in |
Sensory components
The important part of the semiotic control system is the theoretical possibility to produce new signs. Sign image could contain object descriptions in terms of visual recognition system. This method naturally fits the concept of a developing semiotic system. Each object, which has to be recognized, can and must match the sign. This mechanism allows the object base to be enlarged during the work.
Visual recognition system is based on subdefinite models [27]. Method, which recognizes “complex” objects and scenes is described more detailed in [28]. This method is an iterative procedure, which reduces area of uncertainty of variables in agreement with given constraints and reaches the solution. This method has proved its applicability for different scenes' configurations and acceptable speed in comparison with other recognition methods tested on the same class of scenes.
The system for visual object recognition with different descriptions based on this method was proposed in [29]. The first feature of the developed system is the possibility to describe an object as a set of attributes. Attributes characterize an object in different ways such as shape, color, size, and other properties. Program detectors, which match attributes, recognize areas of characteristics on an image and the intersection of all areas is the final position of object. This architecture allows to describe a wide class of objects and to separate them one from another using settings' parameters and composition of attributes. The system is supposed to be used with other types of detectors, for example based on convolutional neural networks. This allows, for example, to detect doorways with any appropriate method, and after this to add some specific information about its color to distinguish one door from another. The second feature is the possibility to combine objects with each other by relations, which also enlarges the class of objects. For example, the simple object named “table”, which is supplied with objects from class “cutlery” by relation “stand on”, could be recognized as “dinner table” instead. And if “table” is supplied with object from “stationary items” it will be “office table” and so on.
Localization system
Integration of a semiotic control system with a localization system is possible with the help of scene recognition mechanism. Such system is meant for localization based on visual landmarks, which are appropriate for wheelchair, functioning in deterministic buildings, such as in the living house or in the office. This localization operates on top, strategic level of system architecture. Recognized landmarks as well as scene they form are sent to semiotic control system of route planning, which creates route as described above. Localization system for a robot based on visual landmarks was approved in [30].
Therefore the only strategic level is not enough for wheelchair movement realization. Elements of route are interpreted by tactic level at sequence of motor commands. And more accurate localization is needed to obtain such sequence. This task is already solved by wide class of methods called SLAM (simultaneous localization and mapping) [31–34]. SLAM methods are quite different by solving procedures and input data. Input data for SLAM could be sensor data, especially provided by range-finders, as well as video data from stereo or mono camera.
It is important to notice that visual recognition system, which is described above, serves for both levels of localization. Objects and more important scenes are recognized at strategic level where they are used for route planning. Objects and their characteristics (such as features and surfaces) are used for SLAM solving processes.
Prototype of automated wheelchair, which has been built for testing, is shown at Figure 3.

|
Figure 3. The intelligent wheelchair prototype that has sonar rangefinders, a video camera, a multichannel motor controller, controllers for the |
The prototype is managed by controller, which interacts with data collection equipment by the computer. Sensor components include set of sonars, which are installed around the perimeter and module of visual object recognition. Reflexes reactions provide safety of movement. Prototype will be used as basis for experiments of combining different types of control impacts. Particularly movement scenario of free walk, lower level reflexes and localization with Monocular SLAM algorithm were tested.
Conclusion
Developing a quality and versatile robotic wheelchair is a challenge that has been attempted for a long time. One of the main problems that is not completely solved is the choice of a means of user interaction that ensures effective and safe control. Signals of the different types such as commands of the joystick, voice, muscular activity, movement of the gaze and encephalographic data can be used, but all these options have significant drawbacks. The precision of instruction recognition is often too low, and the safety requirements do not allow to increase it by longer processing procedures. Some of these interfaces are not universal, others are sophisticated and expensive. Therefore the best way is the developing more intelligent integrated control system capable of planning the wheelchair actions in compliance with safety standards and high reliability that can use many types of interfaces both separately and in combinations. This system will be able to use multi-modal human-machine interface technologies for high-level control. This solution reduces timing requirements for instruction recognition, which allows to improve recognition accuracy and reject invalid and unsafe commands automatically. Also it can use a wider range of human-computer interaction technologies to compensate for a greater number of human functional impairments.
Description of high-level tasks as a sequence of lower-level ones eases the wheelchair control. The task statement in this system is more understandable for the user, and that simplifies adaptation. The application of the developed passive neural interfaces, which will allow using natural human actions for control when considering spatial movement, is particularly promising. Due to this feature it will be possible to skip operator training for using the interface completely.
A semiotic model is proposed to use as a base for describing both the complex behavior and the robot environment. This universal view supports data gathering from heterogeneous sources, application of arbitrary analyzing routines and calling primitive actions. The selected architecture allows combining the components that perform the individual stages of the task and managing their behavior by state machines in a single scenario. Some software modules that perform low-level actions have been developed and tested previously in the robotics laboratory of the Kurchatov Institute as part of a mobile platform control system based on the ROS framework. These are local and global navigation methods, robot motion control, reflex responses, landmark recognition, and accurate positioning. The neurotechnology laboratory of the Kurchatov Institute has developed and tested low-level and high-level control systems based on the registration of gaze movements and myograms. The combination of these components and the flexible interaction description system will ensure the modularity and extensibility of the final product. It will be possible to use situational control tools to plan complex actions and to simplify monitoring in the future.
Financial support. This work was supported by a grant (No.1601 from 05.07.2018) from the National Research Center “Kurchatov Institute”.
Conflicts of interest. The authors have no conflicts of interest to disclose.
References
- World Health Organization. The world report on disability. 2011.
- Report of a consensus conference on wheelchairs for developing countries. Edited by Sheldon S., Jacobs N.A. Bengaluru, India; 2006.
- Shin J., Kwon J., Choi J.,
Im C.-H. Performance enhancement of abrain–computer interface using high-density multi-distance NIRS. Sci Rep 2017; 7(1): 16545, https://doi.org/10.1038/s41598-017-16639-0. - Na’aman E., Shashua A., Wexler Y. User wearable visual assistance system. Patent US 2012/0212593 A1. 2012.
- Clark J.A., Roemer R.B. Voice controlled
wheelchair . Arch Phys Med Rehabil 1977; 58(4): 169–175. - Nishimori M., Saitoh T., Konishi R.
Voice controlled intelligent wheelchair. In: SICE annual conference. IEEE; 2007, p. 336–340, https://doi.org/10.1109/sice.2007.4421003. - Tamura H., Manabe T., Goto T., Yamashita Y., Tanno K. A study of the electric wheelchair hands-free safety control system using the surface-
electromygram of facial muscles. In: Liu H., Ding H., Xiong Z., Zhu X. (editors). Intelligent robotics and applications. ICIRA 2010. Lecture Notes in Computer Science. Springer, Berlin, Heidelberg; 2010; p. 97–104, https://doi.org/10.1007/978-3-642-16587-0_10. - Kim K.-H., Kim H.K., Kim J.-S., Son W., Lee S.-Y. A biosignal-based human interface controlling a power-wheelchair for people with motor disabilities. ETRI Journal 2006; 28(1): 111–114, https://doi.org/10.4218/etrij.06.0205.0069.
- Yulianto E.,
Indrato T.B., Suharyati. The design of electrical wheelchairs with electromyography signal controller for people with paralysis. Electrical and Electronic Engineering 2018; 8(1): 1–9. - Hardiansyah R., Ainurrohmah A., Aniroh Y., Tyas F.H. The electric wheelchair control using electromyography sensor of arm muscle. Int Conf Inf Commun Technol Syst 2016; 2016: 129–134, https://doi.org/10.1109/icts.2016.7910286.
- Jacob R.J.K. The use of eye movements in human-computer interaction techniques: what you look at is what you get. ACM Trans Inf Syst 1991; 9(2): 152–169, https://doi.org/10.1145/123078.128728.
- Fedorova A.A., Shishkin S.L., Nuzhdin Y.O., Velichkovsky B.M.
Gaze based robot control: the communicative approach. In: 7th International IEEE/EMBS conference on neural engineering (NER). IEEE; 2015; p. 751–754, https://doi.org/10.1109/ner.2015.7146732. - Ingram R. Eye-tracking wheelchair developed by DoC researchers featured in Reuters video. 2014. URL: http://www.imperial.ac.uk/news/152966/eye-tracking-wheelchair-developed-doc-researchers-featured.
- Velichkovsky B.M. Communicating attention: gaze position transfer in cooperative
problem solving . Pragmatics & Cognition 1995; 3(2): 199–223, https://doi.org/10.1075/pc.3.2.02vel. - Ben Taher F., Ben Amor N., Jallouli M. EEG control of an electric wheelchair for disabled persons. International Conference on Individual and Collective Behaviors in Robotics 2013; 2013: 27–32, https://doi.org/10.1109/icbr.2013.6729275.
- Swee S.K., Teck Kiang K.D., You L.Z. EEG controlled
wheelchair . MATEC Web of Conferences 2016; 51: 02011, https://doi.org/10.1051/matecconf/20165102011. - Rebsamen B., Guan C., Zhang H., Wang C., Teo C., Ang M.H. Jr., Burdet E. A
brain controlled wheelchair to navigate in familiar environments. IEEE Trans Neural Syst Rehabil Eng 2010; 18(6): 590–598, https://doi.org/10.1109/tnsre.2010.2049862. - Naseer N., Hong K.-S. fNIRS-based brain-computer interfaces: a review. Front Hum Neurosci 2015; 9: 3, https://doi.org/10.3389/fnhum.2015.00003.
- Frisoli A., Loconsole C., Leonardis D., Banno F., Barsotti M., Chisari C., Bergamasco M. A new gaze-BCI-driven control of an upper limb exoskeleton for rehabilitation in real-world tasks. IEEE Transactions on Systems, Man, and Cybernetics, Part C 2012; 42(6): 1169–1179, https://doi.org/10.1109/tsmcc.2012.2226444.
- Osipov G.S., Panov A.I., Chudova N.V., Kuznetsova Yu.M. Znakovaya kartina mira sub”ekta povedeniya [Semiotic view of world for behavior subject]. Moscow: Fizmatlit; 2018.
- Saxena A., Jain A., Sener O., Jami A., Misra D.K., Koppula H.S. RoboBrain: large-scale knowledge engine for robots. 2014. URL: https://arxiv.org/abs/1412.0691v2.
- Skarzynski K., Stepniak M., Bartyna W., Ambroszkiewicz S. SO-MRS: a multi-robot system architecture based on the SOA paradigm and ontology. Lecture Notes in Computer Science 2018; 10965: 330–342, https://doi.org/10.1007/978-3-319-96728-8_28.
- Fikes R.E., Nilsson N.J. Strips: a new approach to the application of theorem proving to
problem solving . Artificial Intelligence 1971; 2(3–4): 189–208, https://doi.org/10.1016/0004-3702(71)90010-5. - Kiselev G.A., Panov A.I. STRIPS postanovka zadachi planirovaniya povedeniya v znakovoy kartine mira. V kn.: Informatika, upravlenie i sistemnyy analiz [STRIPS formulation of behavior planning problem in semiotic view of the world. In: Informatics, management, and system analysis]. Tver; 2016; p. 131–138.
- Karpov V. The parasitic manipulation of an
animat’s behavior. Biologically Inspired Cognitive Architectures 2017; 21: 67–74, https://doi.org/10.1016/j.bica.2017.05.002. - Sutton R.S., Barto A.G. Reinforcement learning: an introduction. IEEE Transactions on Neural Networks 1998; 9(5): 1054–1054, https://doi.org/10.1109/tnn.1998.712192.
- Narin’yani A.S., Borde S.B., Ivanov D.A. Subdefinite mathematics
and novel scheduling technology. Artificial Intelligence in Engineering 1997; 11(1): 5–14, https://doi.org/10.1016/0954-1810(96)00015-5. - Moscowsky A.D. Metod raspoznavaniya stsen na osnove nedoopredelennykh modeley. V kn.: Shestnadtsataya natsional’naya konferentsiya po iskusstvennomu intellektu s mezhdunarodnym uchastiem KII-2018 (24–27 sentyabrya 2018 g., Moskva, Rossiya). Tom 2 [Scene recognition method using non fully defined models. In: 16th Russian conference on artificial intelligence, RCAI 2018 (September 24–27, 2018, Moscow, Russia). Vol. 2]. Moscow: NIU VShE; 2018; p. 27–34.
- Moscowsky A.D. Ob odnom metode raspoznavaniya ob”ektov s ne polnost’yu opredelennymi priznakami. V kn.: Tretiy Vserossiyskiy nauchno-prakticheskiy seminar “Bespilotnye transportnye sredstva s elementami iskusstvennogo intellekta” (BTS-II-2016, 22–23 sentyabrya 2016 g., Innopolis, Respublika Tatarstan, Rossiya) [On a recognition method for objects with non fully defined feature set. In: III All-Russian scientific-practical seminar “Remotely piloted aircraft systems with the elements of artifitial intelligence” (RPAS-AI 2016, September 22–23, 2016, Innopolis, Republic of Tatarstan, Russia)]. Moscow: Iz-vo “Pero”; 2016; p. 137–146.
- Karpov V., Migalev A., Moscowsky A.,
Rovbo M., Vorobiev V. Multi-robot exploration and mapping based on thesubdefinite models. In: Ronzhin A., Rigol G., Meshcheryakov R. (editors). Interactive collaborative robotics. Springer International Publishing; 2016; p. 143–152, https://doi.org/10.1007/978-3-319-43955-6_18. - Davison A.J., Reid I.D., Molton N.D., Stasse O. MonoSLAM: real-time single camera SLAM. IEEE Trans Pattern Anal Mach Intell 2007; 29(6): 1052–1067, https://doi.org/10.1109/tpami.2007.1049.
- Engel J., Schöps T., Cremers D. LSD-SLAM: large-scale direct monocular SLAM. In: Fleet D., Pajdla T., Schiele B., Tuytelaars T. (editors). Computer vision — ECCV 2014. ECCV 2014. Lecture Notes in Computer Science. Springer, Cham; 2014; p. 834–849, https://doi.org/10.1007/978-3-319-10605-2_54.
- Mur-Artal R., Montiel J.M.M., Tardos J.D. ORB-SLAM: a versatile and accurate monocular SLAM system. EEE Trans Robot 2015; 31(5): 1147–1163, https://doi.org/10.1109/tro.2015.2463671.
- Milford M.J., Wyeth G.F., Prasser D. RatSLAM: a hippocampal model for simultaneous localization and mapping. IEEE Int Conf Robot Autom 2004; 1: 403–408, https://doi.org/10.1109/robot.2004.1307183.









